
This article assumes that there is a basic knowledge about embeddings of objects, either text or images. In case you don’t have any notions on the subject, the post on Text Embeddings: the basis of modern NLP explains this concept.
When we want to deal with high dimensional data, such as text embeddings or genomes, we have the problem that classical databases, such as those based on SQL, or even the many noSQL databases, are unable to deal with these data properly.
For example, if you wanted to retrieve every element similar to a specific element, you would have to read every value in the database, and calculate the distances or similarities afterwards. This is extremely inefficient, since, intuitively, not every element is similar, and we only wanted to read those similar elements, since, if we have a database with terabytes of documents, a simple query would be prohibitive.
Generally, this is not a problem in typical databases, since approximate searches are not performed. However, in the case of embeddings, the only type of search possible is similarity search, therefore, the typical indexes that are used are not capable of dealing with this data.
Therefore, we are faced with the problem that our type of data does not fit the use cases that the databases implement. Therefore, there are very specialized databases for this exact type of data, the vector databases, which implement indexes and algorithms optimized for these use cases.
Comparison
To show the effect that these databases have, we can first look at the difference in time to obtain the distances between embeddings from different vector databases with the classical method of computing all distance. For this comparison, we generate completely random, meaningless embeddings, all associated with the same text.
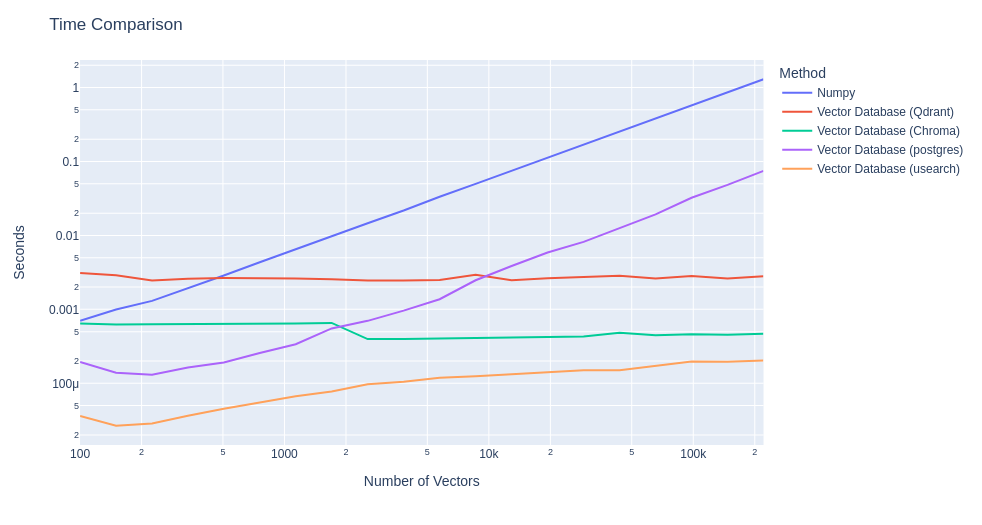
As we can see, the effect of applying a vector database is considerable. We can observe how the execution times using only Numpy grow in relation to the number of elements to be indexed, reaching 1 second with 200,000 elements, while vector databases such as Chroma, Qdrant or Usearch maintain an almost constant time with respect to the number of elements.
Vector databases implement ANN (Approximate Nearest Neighbors) algorithms such as HNSW (Hierarchical Navigable Small Worlds). These algorithms attempt to solve the problem of finding the closest elements to an element without having to observe the entire space containing that element. This is because observing the whole space grows proportionally with the amount of elements in it making the algorithm slower and slower.
Note also that some vector databases implement hardware optimizations, because modern processors often integrate instructions that can operate on vectors natively and extremely efficiently, such as AVX in the case of the x86 instruction set.
Vector Database Use Cases
We now understand that using the appropriate database for this type of data is vital. We may want to index embeddings, after all, it’s nice to know which elements are similar to others from a semantic point of view, but what is the use case where this would be useful to us?
The classic scenario for embedding similarity was semantic document searches, where every document is indexed by its embedding or multiple embeddings, each based on different parts of it, and the search is a natural language text.
For example, we may have a series of product descriptions indexed, and want to find items that are semantically similar to others. Or we may have indexed several legal documents and want to retrieve those that contain information regarding an event.
An old popular use case was image search, where image embeddings were used to search for similar images, or even trying to create mixed embeddings, which could associate text with images.
In order to illustrate this example, we make use of a dataset containing images of plants and where we index these images purely by their embedding. To do this, we will use the Qdrant vector database.
Query plant 1:

Query 1 results:




Query plant 2:

Query 2 results:




As we can see, in this way it is possible to easily retrieve similar images using a vector database and an embedding model.
Currently, the most popular use case and the reason for the rise and popularity of vector databases is due to RAG (Retrieval Augmented Generation). This technique is used to provide the necessary context to an LLM without having to retrain it.
For example, we want to ask it a query on certain products, but since it is not trained on exactly those products, it will invent an answer. The solution would be to feed the description of these products, so that in the context it has everything it needs to solve the query. This context can be stored in a vector database, so that when the query arrives, we search the database for related documents that can provide context, and generate a new query with the added context.
If we apply RAG without proper indexing of the documents, it could require several minutes, whereas with vector databases it may require only a few seconds more. At the same time, we avoid having to retrain the LLM, which can be prohibitively expensive.
Nowadays there are several vector databases or databases that have vector functionalities, such as postgres with the pgvector extension, ChromaDB, Usearch, Qdrant, Pinecone, Redis, Neo4J, MongoDB, OpenSearch, etc. Each of them offers different functionalities and it is necessary to perform a proper study on the functional needs to decide which one to use.
For example, Qdrant is able to scale horizontally with ease because it can run natively on a Kubernetes cluster, while, for example, Usearch scales better vertically. We can see a comparison of different vector databases and the functionalities they offer in Superlinked.
The extra functionalities that can be implemented must also be considered. In this case, we have focused on the main functionality, obtaining embeddings similar to a given embedding. However, depending on the database, elements such as other types of metadata-based filtering, the ability to use sparse embeddings, integration with popular RAG tools such as LangChain or LlamaIndex, the option to quantify embeddings, etc. can be implemented.
Conclusion
Vector databases are specialized databases for calculating similarities or distances, mainly in Euclidean spaces, so that obtaining similar elements is as optimal as possible. This allows certain use cases, such as RAG, to operate in reasonable times.
Therefore, it is advisable to evaluate whether vector data could enrich our data, and whether the systems in use can benefit from them, thus allowing us to enrich our applications.
If you found this article interesting, we encourage you to visit the Data Engineering category for other similar posts and to share it on networks. See you soon!
