
Process Discovery is a family of techniques used to obtain information from event logs and reconstruct the underlying model they have generated. This model can then be used for different tasks such as identifying bottlenecks, monitoring deviations from an ideal process or simply to obtain information.
While simple processes can be easily reconstructed purely from the events they generate, once the complexity of the real world is added, their discovery becomes considerably more complicated. For example, there may be implicit dependencies between tasks, which do not appear in the events. At the same time, we must add the noise that every process in the real world generates. It could happen that on very specific occasions the process is different and, in that case, we would not want the mining process to have those routes in the same way as typical routes.
These complexities have led to multiple solutions for process recreation, each with its advantages and disadvantages. In this article, we will focus on them and give a practical example.
Process Discovery
All solutions generate a representation of the model, which is typically a Petri net or a BPMN model. This is due to the ability of both graphical representations to represent a model. Among the methods for generating such models, we can find some of the most popular categories: Based on abstractions, based on heuristics and based on genetic algorithms.
Process Discovery – Based on abstractions
This method generates a set of rules derived from the relationships between tasks. For example, if a task is in direct succession to another task (x > y), there is a causality relationship (x -> y), they are parallel (x||y), or they have no relationship (x#y). Using these relationships, a table with the relationship of every task to every other task is generated and then transformed into a model.
Of the implementations of this method, the most popular is the algorithm α, but there are many variations of it such as α+, α#, α∗, α++ or β. All the different implementations seek to represent different relationships that others cannot model, such as short loops in α. Therefore, it is important to look at what each algorithm can and cannot model before using it.
Process Discovery – Based on heuristics
A problem that appears when mining processes using the abstraction method is that it is extremely sensitive to noise. Any noise could destroy the relationships between tasks, so this family takes into account the frequency of the event and its relationships. Of these algorithms, the most popular would be Heuristics Miner and its family of extensions.
Process Discovery – Based on genetic algorithms
While the above methods are capable of modeling quite a few model structures, there are several constructs that cannot. Therefore, there is the genetic method, which attempts to search in a global space unconstrained by assumptions regarding the data and their possible relationships. An example of an algorithm implementing this search would be Genetic Algorithm Miner, which, using genetic algorithm optimization, generates a model that best represents the underlying real model.
The main problem with this method is that it tends to be exponential to the number of tasks in the model and is affected considerably by the total number of events to be analysed, being impractical for large event logs.
Practical example of Process Discovery
For the practical example, the Python pm4py library and a hand-created dummy event log are used.
As a simple case study we have the following process map. The vertices indicate the event and, in parentheses, its frequency. On the other hand, the axes indicate how often it leads to another event.

Mining with the α algorithm we obtain the following Petri net, which represents the above process map perfectly.

If, instead of mining using the α algorithm, we do it with a heuristic one, we observe that it is able to recreate the same process only adding more implicit tasks.

Instead, if we add a small loop to the process map, as we can see in the following process map, contact_1 takes contact_2 back a few times.
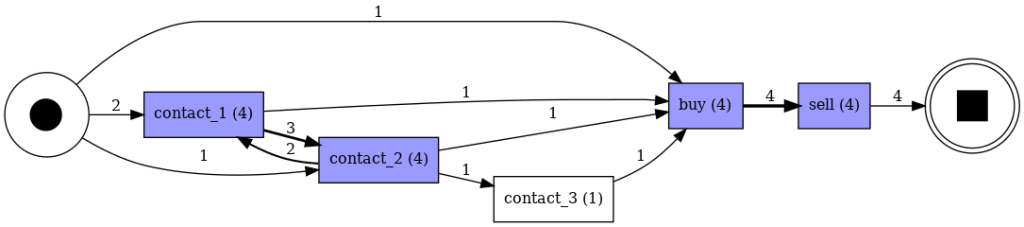
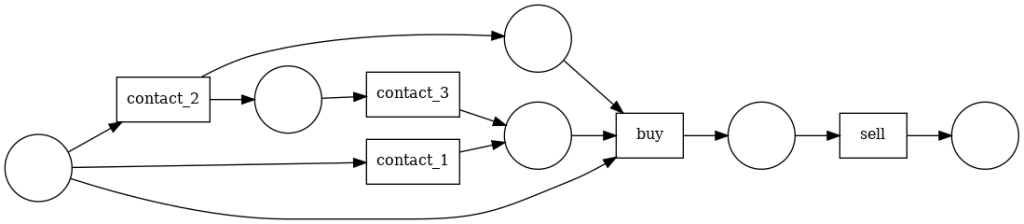
The petri net obtained is not able to achieve this loop.
However, the heuristic miner is able to find a path from contact_1 to contact_2 that generates a loop. However, in the process, the network has become considerably more complicated.
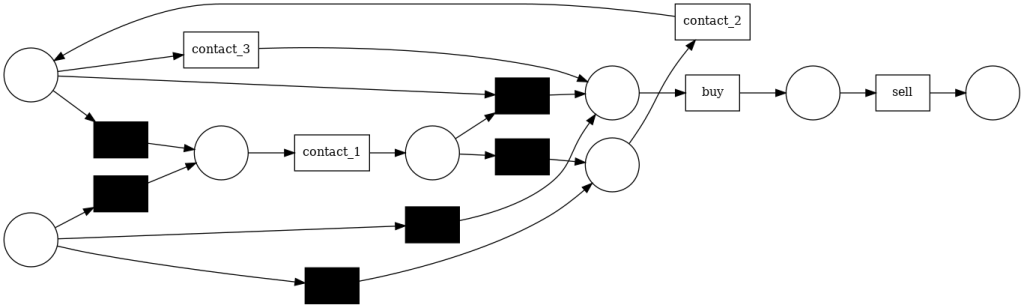
As we can see, the appropriate algorithm can capture different structures that other algorithms do not capture. Therefore, it is necessary to try different algorithms and get an idea of the structures that the process may have in order to model it in an appropriate way.
Conclusion
When we have an event log and we want to obtain information about the underlying models they have, we must resort to Process Discovery, but we must keep in mind that not every method can obtain every model structure or that simple noise can distort it considerably. Therefore, knowledge about the different algorithms is necessary to apply the most appropriate one.
Bibliography
A. Medeiros et al. “Process Mining : Extending the -algorithm to Mine
Short Loops”. In: 2004.
Lijie Wen, Jianmin Wang, and Jiaguang Sun. “Mining Invisible Tasks from
Event Logs”. In: Advances in Data and Web Management Lecture Notes
in Computer Science (), pp. 358–365. doi: 10.1007/978-3-540-72524-
4_38.
Jiafei Li, Dayou Liu, and Bo Yang. “Process Mining: Extending -Algorithm
to Mine Duplicate Tasks in Process Logs”. In: Lecture Notes in Computer
Science Advances in Web and Network Technologies, and Information
Management (), pp. 396–407. doi: 10.1007/978-3-540-72909-9_43.
Lijie Wen et al. “Mining process models with non-free-choice constructs”.
In: Data Mining and Knowledge Discovery 15.2 (2007), pp. 145–180. doi:
10.1007/s10618-007-0065-y.
Changrui Ren et al. “A Novel Approach for Process Mining Based on
Event Types”. In: IEEE International Conference on Services Computing
(SCC 2007) (2007). doi: 10.1109/scc.2007.12.
A. Weijters, Wil Aalst, and Alves Medeiros. Process Mining with the
Heuristics Miner-algorithm. Vol. 166. Jan. 2006.
W. M. P. Van Der Aalst, A. K. Alves De Medeiros, and A. J. M. M.
Weijters. “Genetic Process Mining”. In: Applications and Theory of Petri
Nets 2005 Lecture Notes in Computer Science (2005), pp. 48–69. doi:
10.1007/11494744_5.
If you found this article interesting, we encourage you to visit the Data Science category to see other posts similar to this one and to share it on social networks. See you soon!
