In this article we are going to see what this tool is and how it works. Apache Arrow is present in most of the frameworks in our environment, such as Spark, Dask, Drill, Tensorflow, Kudu, etc. All of them are older than Arrow itself and, in fact, Arrow was born from the need to optimise operations with these frameworks, especially those of serialisation and deserialisation. Arrow was launched in 2016 and is currently among the most valued and downloaded tools of the famous foundation.
What is Apache Arrow?
Apache Arrow is an in-memory data format. It is designed to facilitate the processing of large volumes of data, as it is oriented to work with columns instead of rows. Let’s see how Arrow organises data internally.
| id | name | surname |
| 1 | oscar | garcia |
| 2 | antonio | navarro |
| 3 | javi | cantón |
Traditional memory format
Arrow memory format
| 1 |
| oscar |
| garcia |
| 2 |
| antonio |
| navarro |
| 3 |
| javi |
| cantón |
| 1 |
| 2 |
| 3 |
| oscar |
| antonio |
| javi |
| garcia |
| navarro |
| cantón |
In this example you can see the difference in how the different data buffers are placed in memory depending on the type. The traditional format is oriented to work with transactional data, which in classical databases allows to add data at the end of the buffers. Moreover, this approach is much more oriented to operate with the data of the whole row.
On the other hand, columnar systems are designed to work with all the data in a complete column. One of the great advantages of this new approach is that it allows to operate with large volumes of data, performing operations such as arithmetic, averages, etc., on complete columns.
Another great benefit is the ability to group data of the same type, something that greatly favours compression algorithms. For example, if we work with a whole column of integers, compression algorithms will be able to perform much better compared to a completely random dataset.
What are SIMD operations?
The columnar clustering of Arrow makes it possible to use SIMD operations..SIMD stands for Single Instruction, Multiple Data. It is a processing model used in hardware architecture to accelerate the performance of certain types of operations, especially when dealing with large volumes of data and parallel operations. The concept behind SIMD is that a single instruction can be applied simultaneously to multiple data elements. Let’s see an example.
Example without SIMD
Sum of two arrays of numbers.
Array A = [1, 2, 3, 4].
Array B = [5, 6, 7, 8].
Traditionally, the following operation is performed:
Result = [A[0] + B[0], A[1] + B[1], A[2] + B[2], A[3] + B[3]]
In a traditional approach (without SIMD), you would add the numbers one by one:
1 + 5 = 6
2 + 6 = 8
3 + 7 = 10
4 + 8 = 12
In the end, the result would be the array [6, 8, 10, 12], but the process is sequential.
SIMD Example
With SIMD, instead of adding a couple of numbers at a time, all the numbers of Array A and Array B are loaded into two different registers, one for each array. SIMD would process those registers and sum the values of all the elements at the same time.
[1, 2, 3, 4] + [5, 6, 7, 8] = [6, 8, 10, 12]
The end result would be the same array [6, 8, 10, 12]. However, the interesting thing here is that all the additions are done simultaneously, rather than one by one. This allows for much faster operations, especially when working with larger data sets.
Multi Framework
As mentioned above, Apache Arrow is designed to integrate with different frameworks and languages. In this github repository, we can see all the different language implementations of Apache Arrow. The implementations are used for integration into some of the most famous frameworks.
The main reason for using this standard for processing large volumes of data is that it facilitates integration between your own nodes, services and other services that work with Arrow.
What is done is to pass the memory locations where the data is located and, as all the interested parties know the standard, they will be able to read it without any difficulty. This reduces parse and transmission times between services to 0.
Internal format of Apache Arrow
In this section we will analyse the internal format of Apache Arrow. The exercise we are going to do can be repeated and explored on your own. For this, we only need to have the numpy, nanoarrow and pyarrow libraries installed.
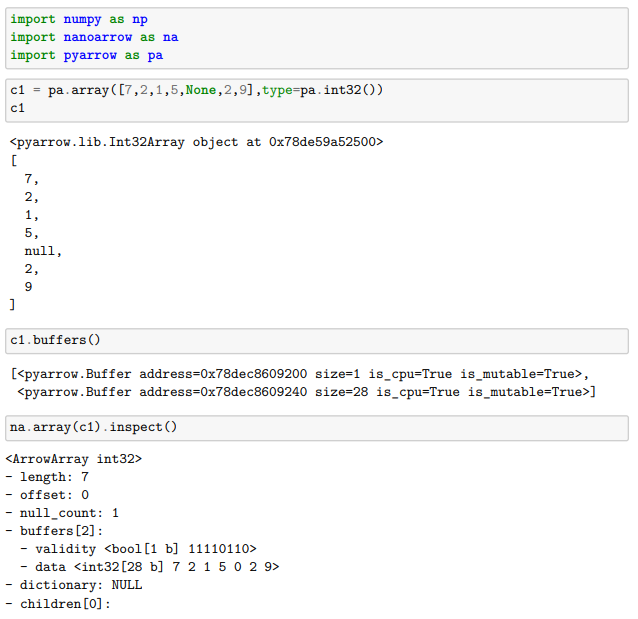
In this example, we create an array of integers with some null.
If we check the object’s buffers, we see that there are two buffers.

These two buffers materialise the existence of two concepts recurrently used by Arrow: vailidity bitmap buffer and values buffer.
Validity bitmap buffer
The validity bitmap buffer is responsible for storing the information of the values that are null within the array. To do this, it generates a bit array, which is a memory space with a length in bytes. This length is the size of the original array divided by 8 and rounded up, so as a practical example, if we have a column that is represented as an array of size 9, the bitmap buffer will have 2 bytes.
Like any bitmap, it will represent as a mask which values within our array are null, so it will mark their position with a 0 if they are null and 1 otherwise.
If we inspect our example bitmap buffer, we can check the content.
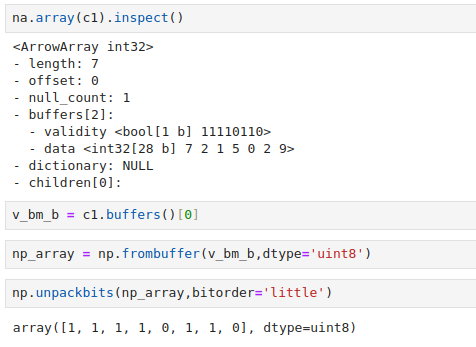
In our example, we see that, despite having 7 values, the length of the bitmap buffer is 8. This is due to the rule we stated earlier, 7/8 and rounding up, which would give 1 byte, which would be 8 bits. And where the last bit is not being used, as it exceeds the length of the values, it will also be marked as a 0.
Values buffer
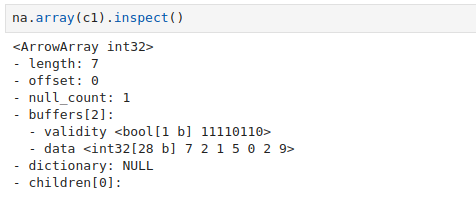
This buffer contains the values corresponding to the data in a contiguous format in memory, allowing efficient access. The format of the buffer varies depending on the type of data contained in the column (integer, float, string, etc.).
In our example, the buffer is 28 bytes. This is because the data type is int32, which means that we will need 4 bytes to store a single value. Since we have 7 values, we will have a buffer of 28 bytes.
Conclusion
Apache Arrow has revolutionised big data processing by offering a highly efficient in-memory format specifically designed to optimise columnar data access and manipulation.
Its integration with SIMD operations and the ability to standardise communication between different frameworks without the need for costly serialisation processes make it a key tool in the modern data ecosystem.
In this introduction, we have seen how to analyse Arrow’s internal format and, in future posts, we will explore more data types and look at other scenarios.
That’s it! If you found this article interesting, we encourage you to visit the Software category with all related posts and to share it on social media. See you soon!
