
When we are working with relational databases, it is usual for some queries to be extremely slow. This can be due to different reasons, but the most common is that the data access pattern that the query demands is not one that the database design supports properly, as is often the case in queries that have to join many tables. The second most frequent cause is the lack of indexes or their bad design, points that we will analyse in this article.
All the examples that will be shown during the development of the post are about PostgreSQL with sample data.
What is an index?
An index is a way of organising pointers to the data stored in the database, so that you don’t have to read the whole database to answer queries. But, of course, there are countless ways to organise such data, and each has its advantages and disadvantages.
The most important thing to keep in mind is that an index must be stored in the database itself, as well as kept up to date to answer queries. Therefore, simply adding indexes can make the database worse. In this article, we will discuss the most typical indexes and the strategies followed to use them, as well as examples of the effect they produce. All of them will be compared with a simple query that, due to the lack of indexes, generates a sequential reading of the whole table.

As an example to compare to, this is a simple query with a condition that needs to scan the entire table if there are no indexes.
B-Tree index
B-Tree indexes are the indexes that relational databases usually have by default on the primary key. They can be considered an extension of binary search trees where, instead of two children per node, they can have more. This is to optimise disk access times, especially on hard disks.
These indexes keep the data sorted, easily allowing all kinds of queries. However, they have the limitation that they have to be rebalanced from time to time, as they can naturally become unbalanced and take up a considerable amount of space.
There are generalisations of B-Trees, such as GiST (Generalised Search Tree), which allow any type of data to be indexed with any operation. However, their use usually requires the creation of an implementation.
We create the index as shown below:
CREATE INDEX btree ON stocks USING BTREE (symbol);When using an equality, we can see that it uses the index (due to PostgreSQL optimisations, the index is in turn used to create a bitmap).

The index works in the same way under non-equal conditions.
Hash index
A hashed index only stores the hash of the given field, which allows the index to be considerably smaller in size and to save rebalancing. However, since only the hash is stored, it can only be used under equality conditions.
We create the index as follows:
CREATE INDEX hash ON stocks USING HASH (symbol);
If an equality condition exists, the index is used without problems.

If we do not execute an equality condition, we see how it needs a sequential scan.
Multi-Column Index
Indexes are not limited to a single field, but can also be defined on several fields. However, we have to take into account what effect this has, as there is an order in the fields.
For example, if we define an index on (A,B), making a query that filters on both will use the index, and if we only filter on A, it will also use the index. But if we only filter on B, this index cannot be used.
Next, we create the index:
CREATE INDEX btree_multi ON stocks USING BTREE (symbol, date);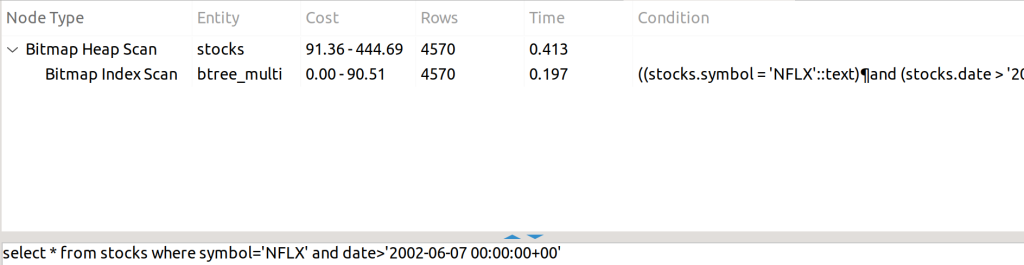
Both conditions can be consulted in the index, so you can use it without any problems.
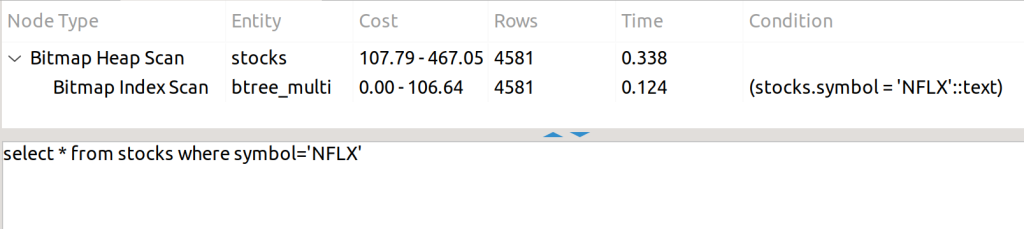
The condition is contained in the index, so you can use it.
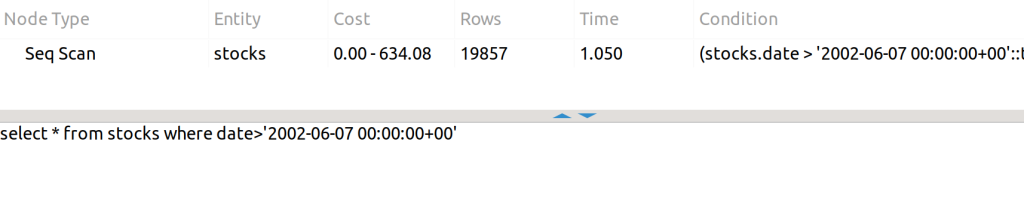
Although the condition is included in the index, the order is wrong and it is not able to use the index, as it was (symbol, date) and we cannot ask only for date.
Covering Index
A specific case of index is the ‘Covering Index’. These are indexes of any type that contain all the information necessary to answer the query, so that it is not necessary to access the indexed table. These indexes are optimal from the point of view of the time required to process a query. However, they have the limitation that they are usually created to cover certain very critical queries, thus improving execution time but slowing down other processes by having to maintain more indexes.
Some databases offer explicit support for these indexes, such as PostgresQL, which allows you to add extra columns to an index to transform it more easily into a Covering Index.
Next, we create the index:
CREATE INDEX btree_multi ON stocks USING BTREE (symbol, date) include (high);
Since all queried data are present in the index, an index-only scan can be performed.
Index expressions
Sometimes we have a query that applies a specific expression or function on the data and normal indexes cannot be used. For such cases there are indexes with expressions, which not all databases implement but which offer considerable improvements in these specific situations.

Without index, we have to run a sequential scan of the whole table.
We proceed to create the index:
CREATE INDEX btree ON stocks USING BTREE (lower(symbol));
With the index, we can filter directly by the expression.
Conclusion
We have seen that by generating the appropriate indexes it is possible to optimise queries, so that only the desired data is accessed, thus reducing both cost and execution time. However, it is important to define the appropriate design of such indexes, taking into account which queries can help and how they should be constructed to obtain the greatest possible benefit.
If you found this article interesting, we encourage you to visit the Data Engineering category to see similar posts to this one and to share it on social networks. See you soon!
