
The arrival of Apache Spark 4.0 is a long time coming, but to encourage the community, the famous foundation has released a preview access of the version. A few months ago, the Databricks developers gave us a small preview of what’s in store by announcing the new features in a video. In this article, we will summarise and explain the main new features of the new version.
Team Apache has tried to update the famous framework looking to improve efficiency, extending the compatibility with APIS and development languages and making it easier to use for developers and data analysts. If you are a fan of this tool, you can’t miss the new features that were shown in the presentation of Spark 4.0 and that we will discuss in detail in this post.
New features in Spark 4.0
Spark Connect
With Spark 4.0 comes Spark Connect, a client API that sits between Spark users and the driver, unifying the way they communicate with the system. Thanks to this new implementation, users will be able to connect to Spark in a more flexible and lightweight way.
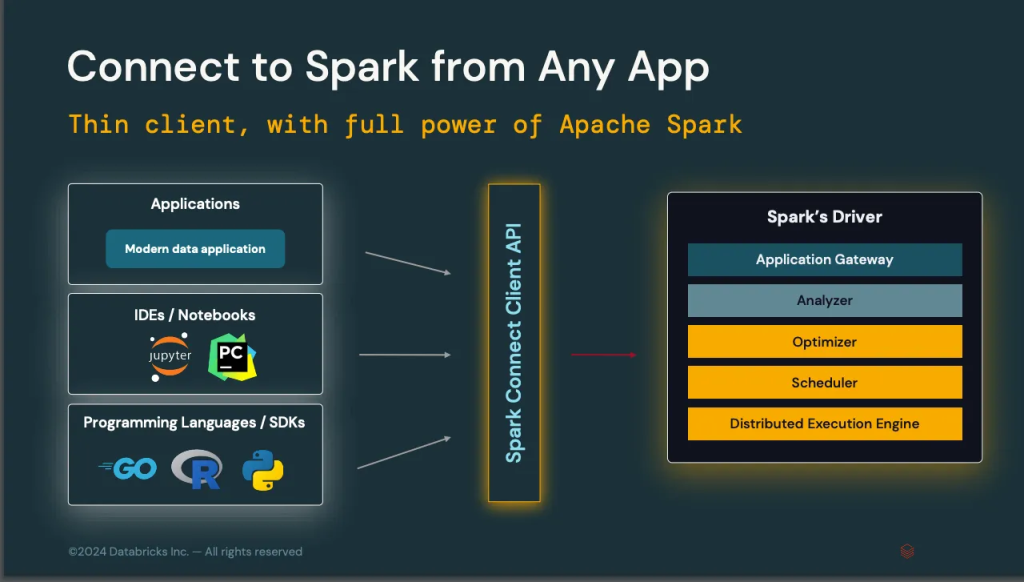
This new API can be easily installed with pip install pyspark-connect. This library weighs only 1.55 MB, compared to 355MB for PySpark.
With this new API, the latency of interactive REPL queries is improved.
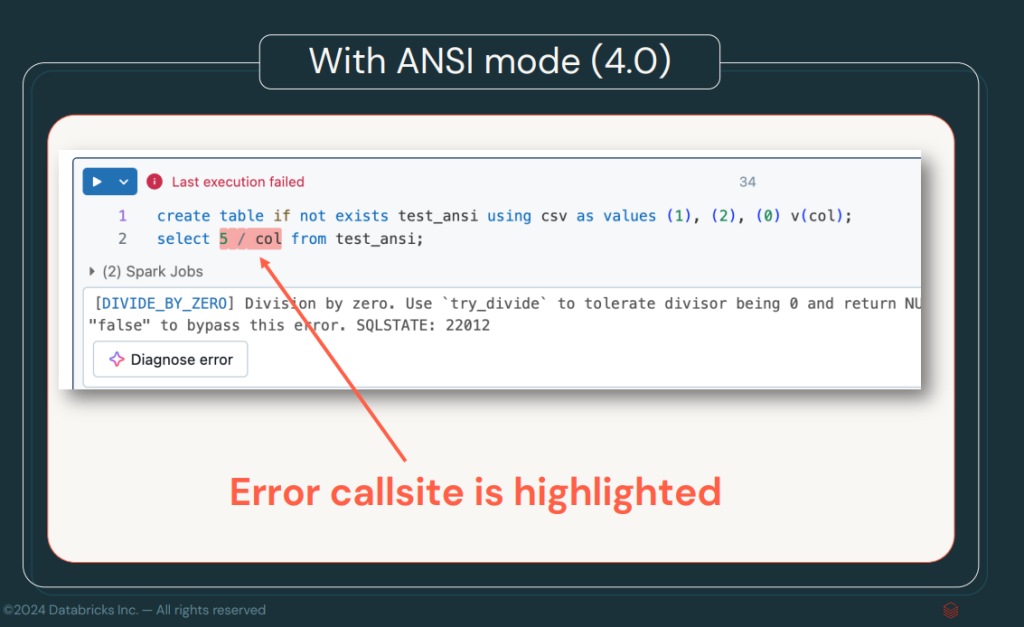
ANSI Mode by Default
In this new version, ANSI Mode will be enabled by default, which in previous versions would have needed to be enabled with spark.sql.ansi.enable=true. This mode ensures that SQL operations conform to the rules and behaviours set out in the ANSI SQL standard, ensuring greater compatibility with other SQL systems and databases. The main advantage is the robustness of SQL statements and improved error handling.
The ANSI mode will allow faster error detection by Spark. In another post, we can discuss this standard in more depth, but, basically, it allows us to avoid invalid conversion errors, division by 0, operations that violate the integrity of the data, etc.
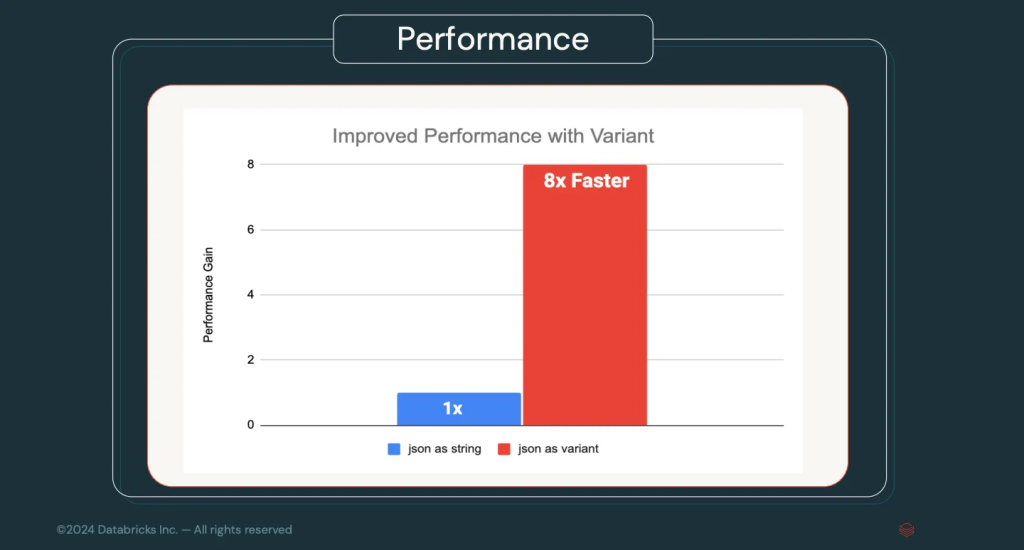
Variant Data Types
Until now, complex data such as JSON was treated as text strings and structured using the PARSE_JSON operation. With the new Variant data types, Spark will be able to handle this data natively, promising up to 8x faster performance for queries involving JSON.
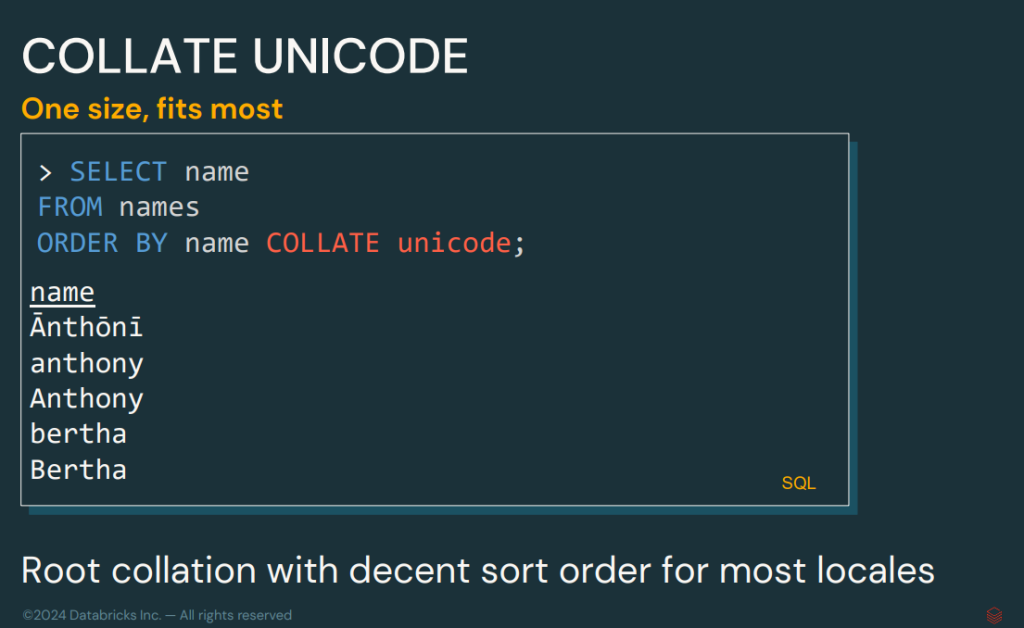
Collation support
Collation support introduces the ability to sort and compare data according to locale. This system will make it easier to work with operations between alphabets, languages, upper and lower case, among other examples.

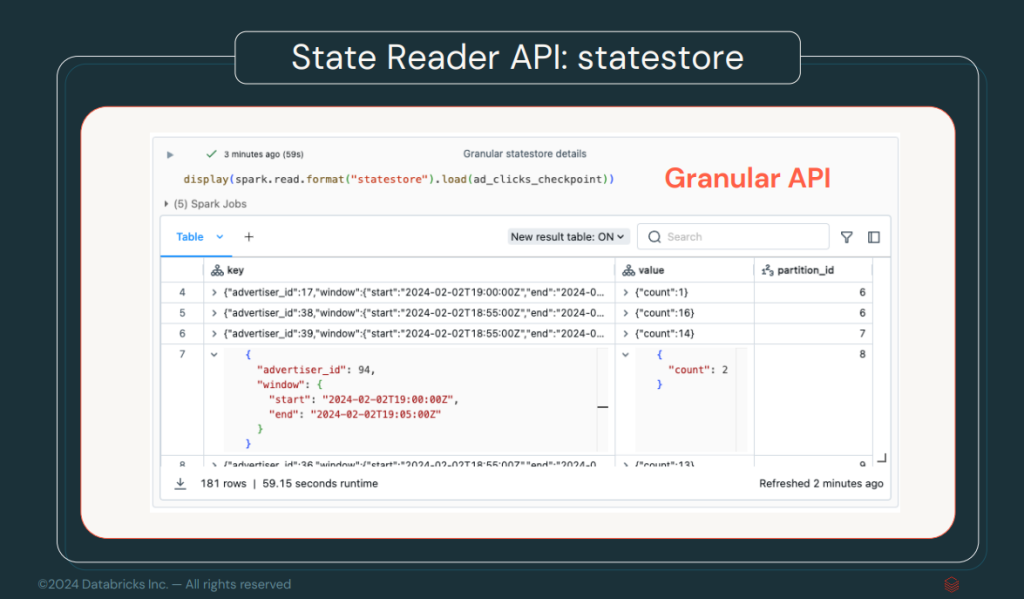
Streaming State Data Source
One of the big improvements in streaming processing is the addition of the Streaming State Data Source. This new Data Source allows access to the internal state of a streaming application. This is achieved by connecting to the checkpoint stored, for example, in an S3, improving the visibility of the state in real-time applications.
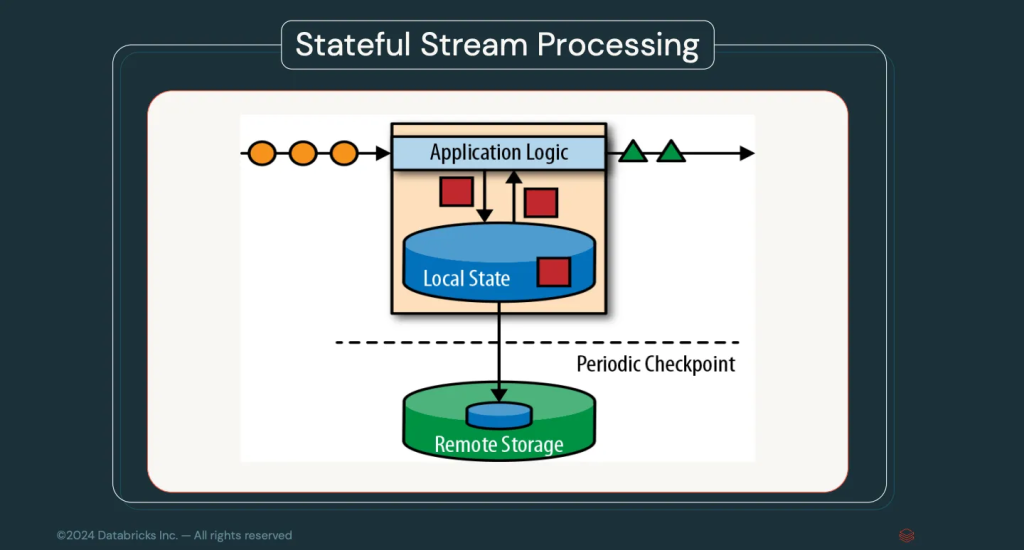
Arbitrary Stateful Processing V2
In this version, the capacity of this well-known functionality is extended. Remember that this system gives us the possibility to save a state in a stream operation. For example, in a cumulative sum, keep the result of the sum in each event of the stream to be able to continue counting.
On the other hand, in this version the system supports the streaming status for each grouping in a groupByKey. The status can be updated as the current group is evaluated and the update will be available at the next event.
Apache Spark 4.0 Extensions
Python Data Source for Streaming and Batching
This feature is one of the most important and, from my point of view, the one that will give the most play to the community. Support for DataSources development has been extended to Python natively. This will allow the large Python community to develop their own DataSources in a very organic way and make them available to other users.

Dataframe.toArrow and GroupedData.applyInArrow
The development team is fully committed to Apache Arrow. This time, Apache Arrow is integrated for the development of UDFs in Python. The Dataframe.toArrow method simplifies the conversion between a PySpark DataFrame and a PyArrow table. GroupedData.applyInArrow allows you to parallelize work in groups, which significantly improves performance and convenience for intensive tasks.
Native XML Connector
One of the new features is the addition of a native XML parser after integrating a third-party library that was used for this purpose. This streamlines the loading and processing of XML data without relying on external libraries.
spark.read.xml(‘/path/to/my/file.xml’).show().Databricks Connector
As expected, Databricks has worked with and influenced development to support their ecosystem. As such, they have added an improved Databricks connector, allowing Databricks SQL tables to be loaded via the jdbc:databricks prefix, streamlining the connection and access to these systems more efficiently.
spark.read.jdbc(
"jdbc:databricks://…",
"my_table",
properties
).show()Delta 4.0 Extension
This new version of Spark includes support for Delta Lake 4.0 along with all its new features.

On the other hand, the concept of Liquid Clustering is introduced to improve reads and writes in DeltaLake and make them much faster.
The way to launch these optimisations is on a table already created and that has a clustering by a key. In addition, the OPTIMIZE tbl. operation is performed, which is responsible for improving the index and clustering of the created table in a way that promises the following increments.

Custom Functions and Procedures
Python UDTF
Here comes a new feature that, from my point of view, will be widely used by the community. This is the option to create Python UDTF (User-Defined Table Functions), which allow you to return a complete table instead of scalar values. This opens up a whole new range of possibilities for custom data processing.
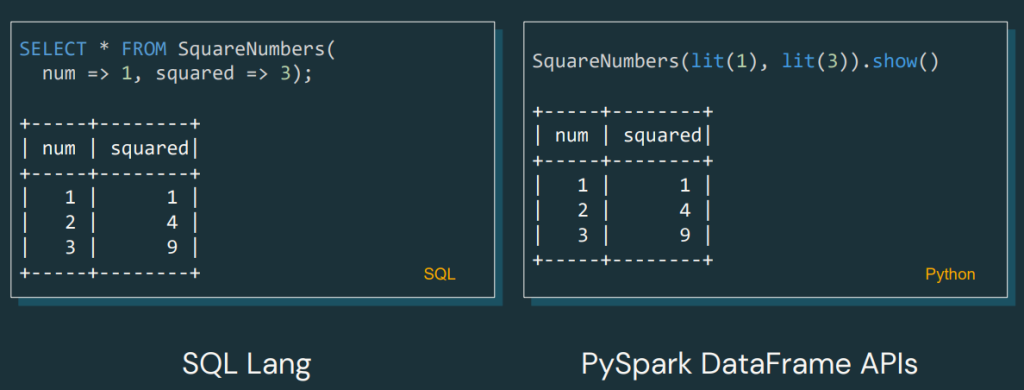
Example:
We can see here how the UDF will return the DataFrame of the squares.
UDF Optimised with Arrow
UDFs were already optimised with Arrow since Spark 3.5, but now, in Spark 4.0, they are enabled by default. This improves serialisation and deserialisation speed, making the processing of user-defined functions faster and more efficient.
In the following image, we can see a benchmark of UDF performance.
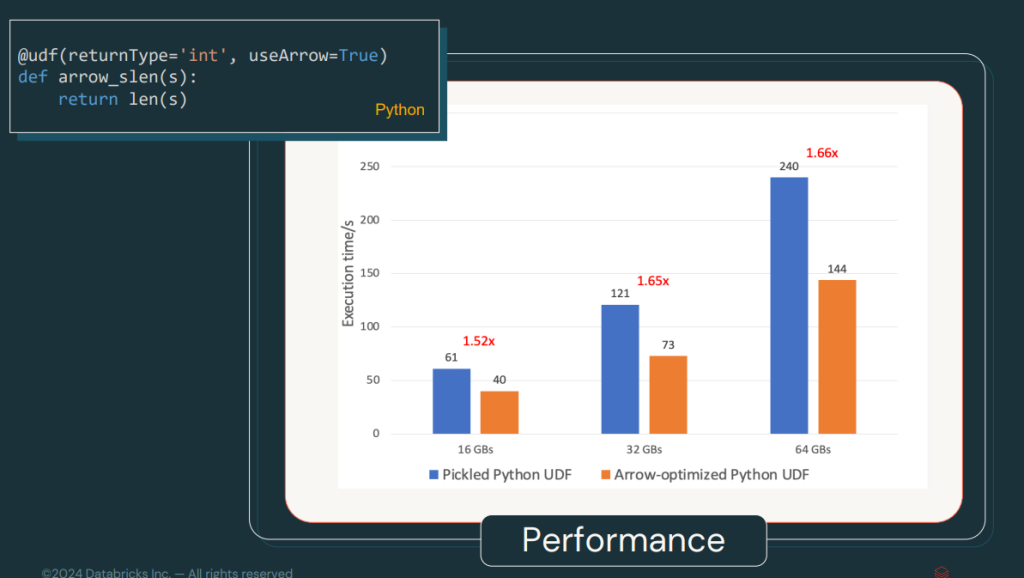
One of the secrets to this improvement is Arrow’s UDF pickelisation system, which makes information sharing much lighter.
SQL UDF/UDTF
It is now possible to create custom functions and procedures using the SQL DSL, which allows you to save them for later use and that could be understood as a kind of Stored Procedures for Spark.

SQL Scripting
A significant new feature is the support for SQL scripting with control operations such as IFs, WHILE, FOR, CONTINUE and many others, which improves the programmatic logic within SQL queries.
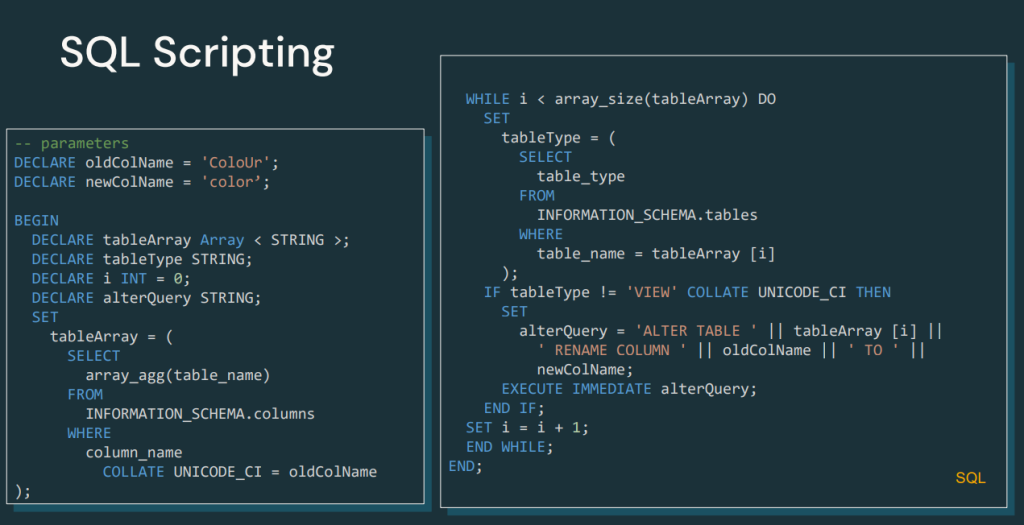
This new feature will open up a range of possibilities. For example, integration with ELT frameworks such as DBT, which can be easily incorporated and even add some logic, bringing us closer to imperative programming.
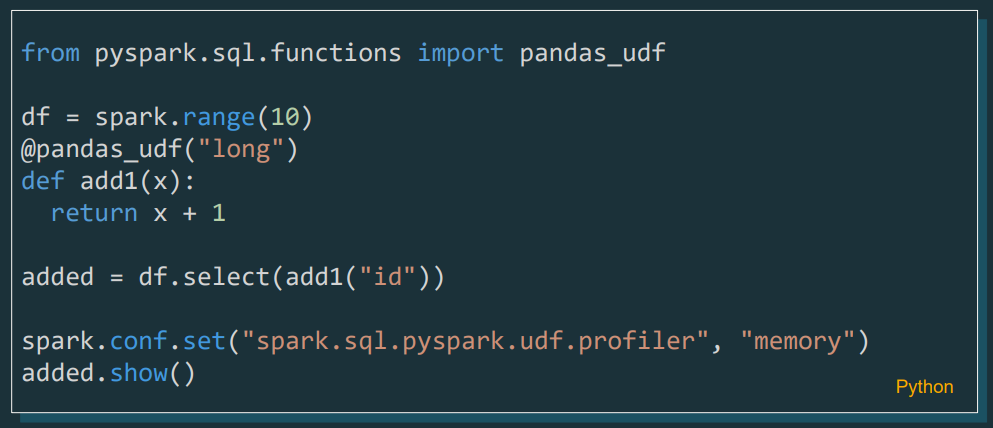
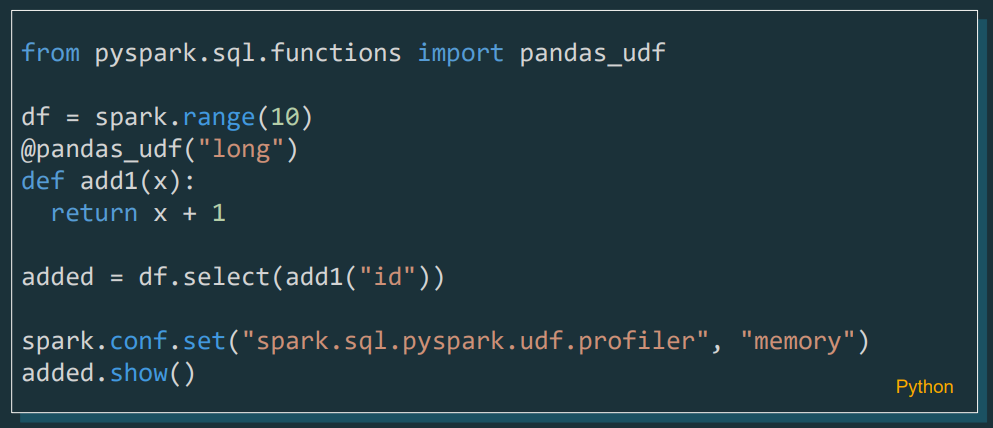
Pyspark UDF Unified Profiler
A profiler for UDFs is now included in PySpark, which will allow developers to analyse and optimise the performance of their custom functions in more detail, both in terms of memory used and time spent for the function.
Usability and Experience Improvements
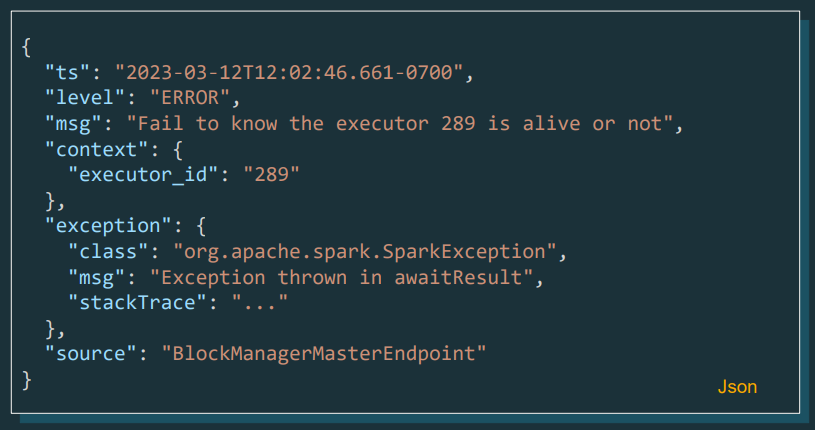
Structured Logging Framework
Structured logging is one of the major enhancements in this release. Logs can now be analysed and queried directly from Spark, allowing system logs to be loaded for further analysis.
We went from:

To a log format that we can load and read with Spark:
Improved Error Messages and Conditions
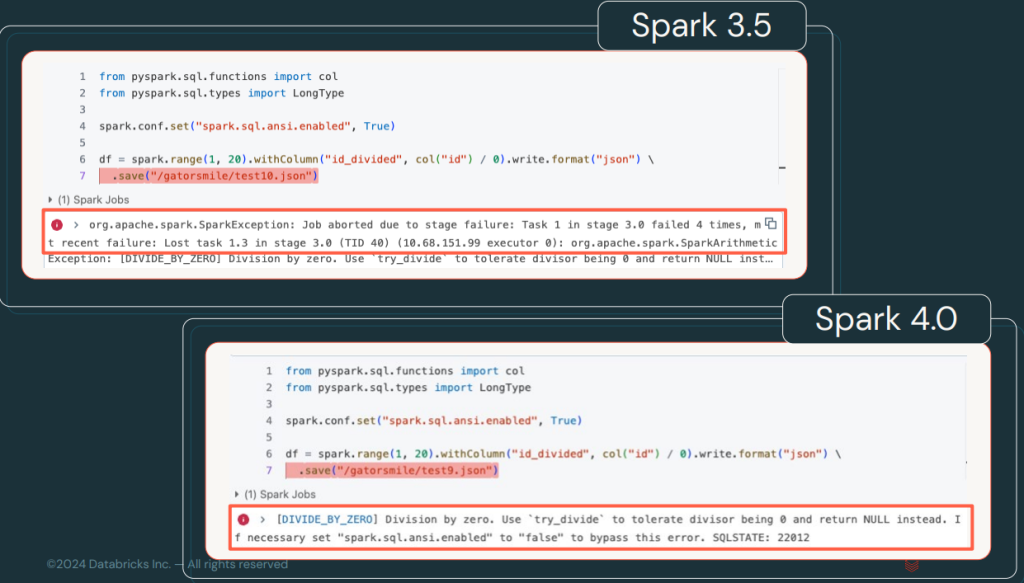
Errors in Spark 4.0 will now be categorised and classified with specific codes that allow faster identification and troubleshooting. This improves documentation and makes debugging easier.
A list of error conditions, codes and states that Spark SQL can return can be found in the Spark documentation.
To better visualise the change, let’s look at the difference between the errors in one version and the other.
Behavioural Changes
Major adjustments have been made to backwards compatibility and version management. Impact categories will allow you to better evaluate changes when upgrading Spark and determine if they affect your workflows.
In this part, we will have to see how it is applied, as it changes the way future versions are incremented, a number of categories have been made and, depending on the category of the change, the version will be modified so that the community can understand if they can migrate to the new one without risk.
Improved Documentation
The new Spark 4.0 documentation will include more examples, environment configurations and quick guides to facilitate the adoption of the new features. In addition, support for more robust data type conversions will be included.
Conclusion
Spark 4.0 has been a long time coming, but it brings new features that I believe are very much in tune with community trends. For example, we can highlight the improvements in the integration with Python and SQL, which I believe was necessary to reduce the complexity of access to the framework.
On the other hand, the inclusion of new connectors, improvements in log handling and a focus on usability make Spark 4.0 a more accessible and powerful platform. Whether you’re working with Big Data, Machine Learning or real-time streaming, this update brings improvements that will power all your projects.
