
What is a Data Catalogue seems very intuitive and that anyone minimally initiated in this world would understand. But putting it into practice and implementing it is a bit more complicated. For those who are not familiar with this concept, I like to explain it with an analogy I read some time ago.
Imagine you are in a giant supermarket, where there are thousands and thousands of products, and you need to find something very specific. For example, we need to locate a chocolate candy, which is wholemeal and has no traces of egg or lactose. If the supermarket is fairly organised, the most logical thing to do would be to go to the aisle or the shelves where the sweets are placed, but we will probably have to check many labels and products until we find the one we are really looking for.
The Data Catalog concept helps us to make this process much faster. If we had a system that we could ask for a series of keywords (such as chocolate, wholemeal, egg-free and lactose-free), it would probably tell us the exact place where to find our product.
This is exactly what a Data Catalog does for us, with the added bonus that it also provides a detailed description of the product with information about its origin, format, traceability, quality metrics and even how it is used.
However, when we talk about the implementation of a Data Catalog in an organisation, we have to be very clear that it is not just a data inventory, but it must also provide us with a series of characteristics that can be useful in our day-to-day work.
In this post, we are going to talk about what conditions a Data Catalog system must fulfil and see some of the alternatives that exist in the market.
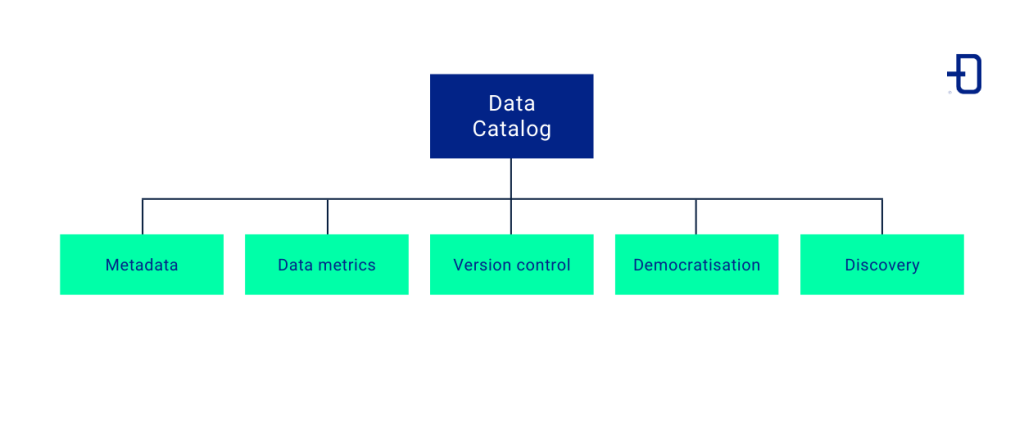
Key features of a Data Catalog
Metadata
To talk about Data Catalog is to talk about metadata. In fact, basically, a Data Catalog is a metadata store. There are a multitude of frameworks that serve as a guide and even allow us to restrict the variety of metadata that can be entered. We can divide them into the following categories:
- Technical metadata: These are those purely technical aspects that help us in the management of information, such as, for example, data extensions, compression data, structure data, or where the data is located at a physical level.
- Business metadata: These are used for business categorisation. For example, departments, locations, definitions, relationship to business processes or conceptual owners of the data.
- Operational metadata: Helps to define traceability and inheritance of data.
- Security metadata: Defines who should have access to the information both by department at the business level and by security at the ISO or legal level. It helps to establish different levels of access depending on the criticality of the data.
Data Metrics
Some Data Catalog systems integrate the ability to define metrics about the data. Most of these metrics are oriented to purely quantitative characteristics of a dataset. In other words, we can find frequency averages, repetition statistics, data volume, etc.
The metrics help the user to better understand the data without the need for analysis and also to determine if any operational process is occurring that is not contemplated within the Data Quality and Data Observability policies that may be corrupting the data.
Version control
In a similar way to the version systems in software development, in information management environments, data can also be versioned and have validity indicators for each one of them. This is a very important capability, especially when we have to perform data analysis in past contexts. Some Data Warehouse tools allow this type of analysis with their time travelling systems.
Democratisation and discovery
The main advantages of having catalogued data are to be able to share it with other users, to make it public for the company or to have the possibility to distribute it selectively. This is something that Data Catalog systems provide, because that is what they are designed to do. However, not all of them have the ability to automatically integrate new data into their catalogue.
Within the data management ecosystem, many new and existing tools are including automatic information discovery and tagging systems. This is mainly due to the use of AI in the data classification process, but it is not a foolproof function. Often, the tagging needs to be corrected and, for the time being, many systems have opted to do suggested tagging, but this helps the process of updating and regenerating the data.
Which Data Catalog tool to choose?
When deciding which tool to use, we will have to take into account the functional characteristics mentioned above. Beyond that, there are many other particularities to take into account, such as the types of licences the tool will have or how many people will have access to it, because if it is a proprietary tool and we need many licences, it could increase the budget of the solution.
On the other hand, we must make sure that it is able to integrate and support our data sources. For example, if we are using DBT and the tool has Data Observability capabilities, we do not want to use a system that does not allow us to properly integrate our ETL tool.
We also have to consider whether we want to extend data management to a higher level of Data Governance (and therefore the Data Catalog system may be too limited to take into account the global management of the data), the standard behind the tool in terms of specification (which is unique to the tool and could make it difficult for us to migrate to another method in the future), etc.
In Git there is an interesting resource that can help us compare the different Data Catalog tools that currently exist in the market.
From my experience, I would recommend giving DataHub a try. It is a very complete platform that has been developed by Linkedin and that offers a wide variety of services not only oriented to Data Catalog, but also to Data Governance. Also, you can have a look at a demo of DataHub if you are interested.
In future articles, I will talk in more detail about DataHub and how it can be integrated. In our case, it fits very well with the ecosystem of tools that we use in Damavis to develop the Big Data technology solutions that we implement for our clients, such as DBT for the ELT/ELT part, Airflow for orchestration and automation and Snowflake or BigQuery as Data Warehouse.
Conclusion
In summary, an effective Data Catalog is a strategic investment that can transform the way organisations manage, share and use their data, improving operational efficiency and promoting a Data Driven culture, where decision making is based on the unequivocal reality shown by the data.
Implementing a Data Catalogue in an organisation is a very important and non-trivial step. We must be aware that Data Catalog not only allows us to find specific data quickly and efficiently, but also provides us with a number of essential features such as metadata management, data metrics, version control, and the ability to democratise and discover information.
If you found this article interesting, we encourage you to visit the Data Engineering category of our blog to see posts similar to this one and to share it in networks with all your contacts. Don’t forget to mention us to let us know your opinion @Damavisstudio. See you soon!
